
この記事では、Pythonで画像を加工するためのライブラリ「PyOCR」とOCRエンジン「Tesseract」を使用して、画像ファイルから文字を認識させる処理を作る方法を解説します。
目次
使用するライブラリ等
- PyOCR
- Pillow
- Tesseract
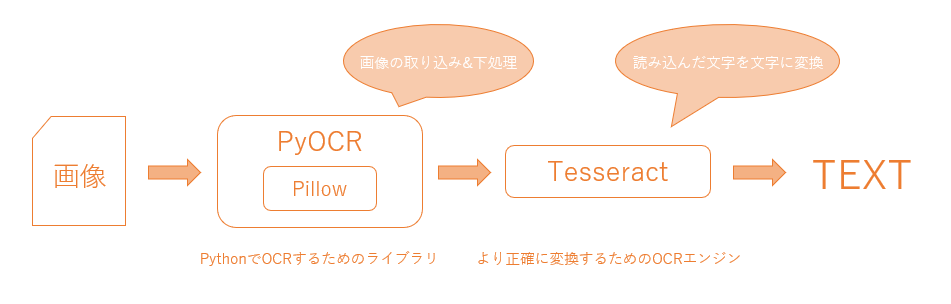
PyOCR(パイオーシーアール)
PythonでOCR(画像から文字を読み取ってPCが読み取れる文字コードに変換する)を行うためのライブラリ。
PyOCRをインストールすることで、この後説明する「Pillow」もインストールされます。
(内部でPillowを使っているってこと…?)
Pillow(ピロウ)
Pythonで画像を加工するためのライブラリ。画像の切り抜きなどの加工ができる。
Tesseract(テッセラクト)
GoogleとHPが共同開発したOCRエンジン
これはPython用のライブラリではないため直接制御できない。
そのため、PyOCRでTesseractのエンジンを使うように橋渡しする必要がある。
PyOCRをインストールする
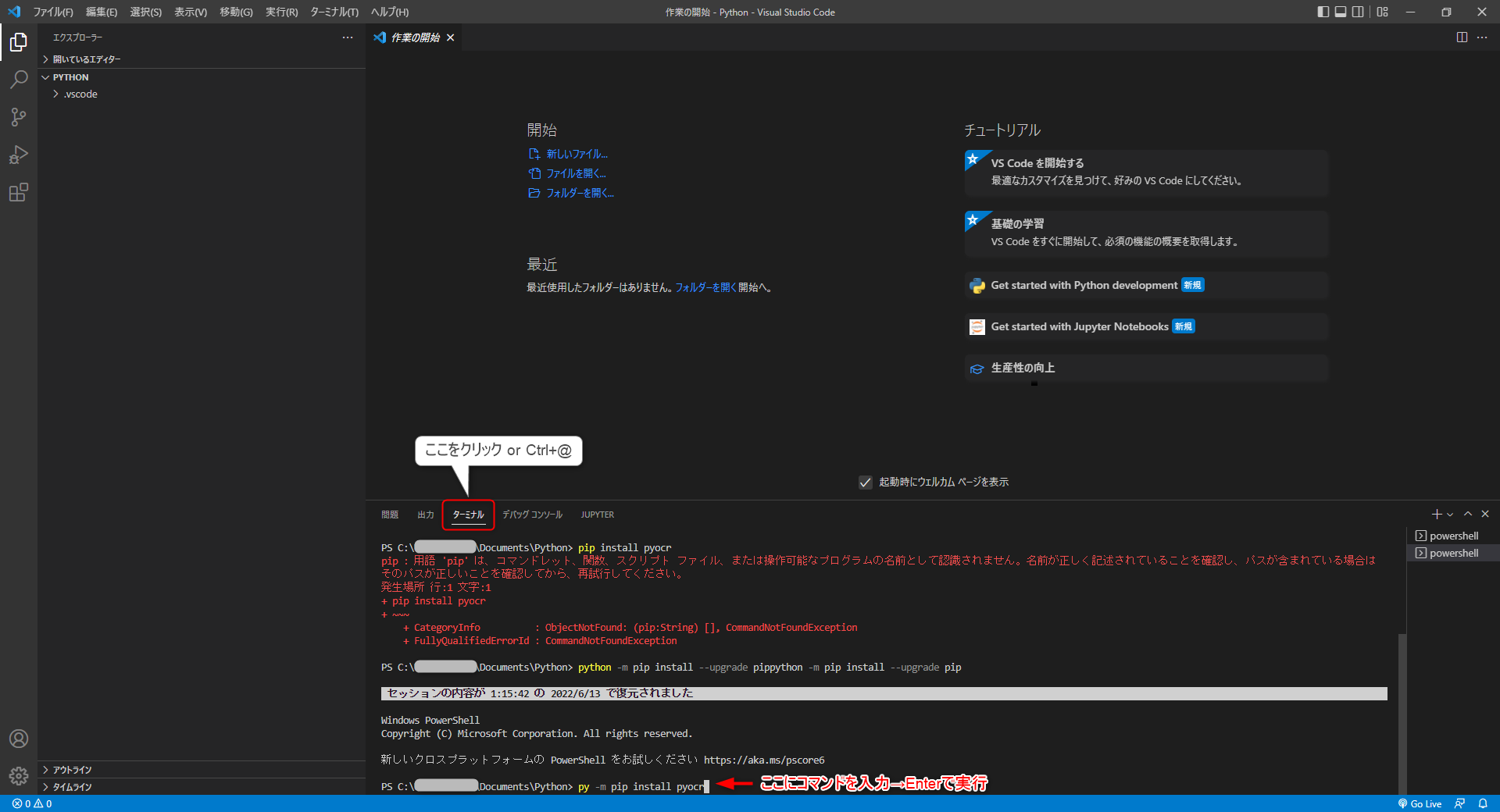
VSCodeでライブラリをインストールしてみましょう。
(管理人も書きながら初挑戦です)
ライブラリのインストールはターミナルで「pip」というコマンドを使います。
PyOCRをインストールするコマンドは以下の通りです。
ちなみに、最後の”pyocr”を他のライブラリ名に変更すれば他のライブラリもインストールできるみたいですね。
py -m pip install pyocr
インストール完了!
PyOCRと一緒にPillowもインストールされていますね。

Tesseractをインストールする
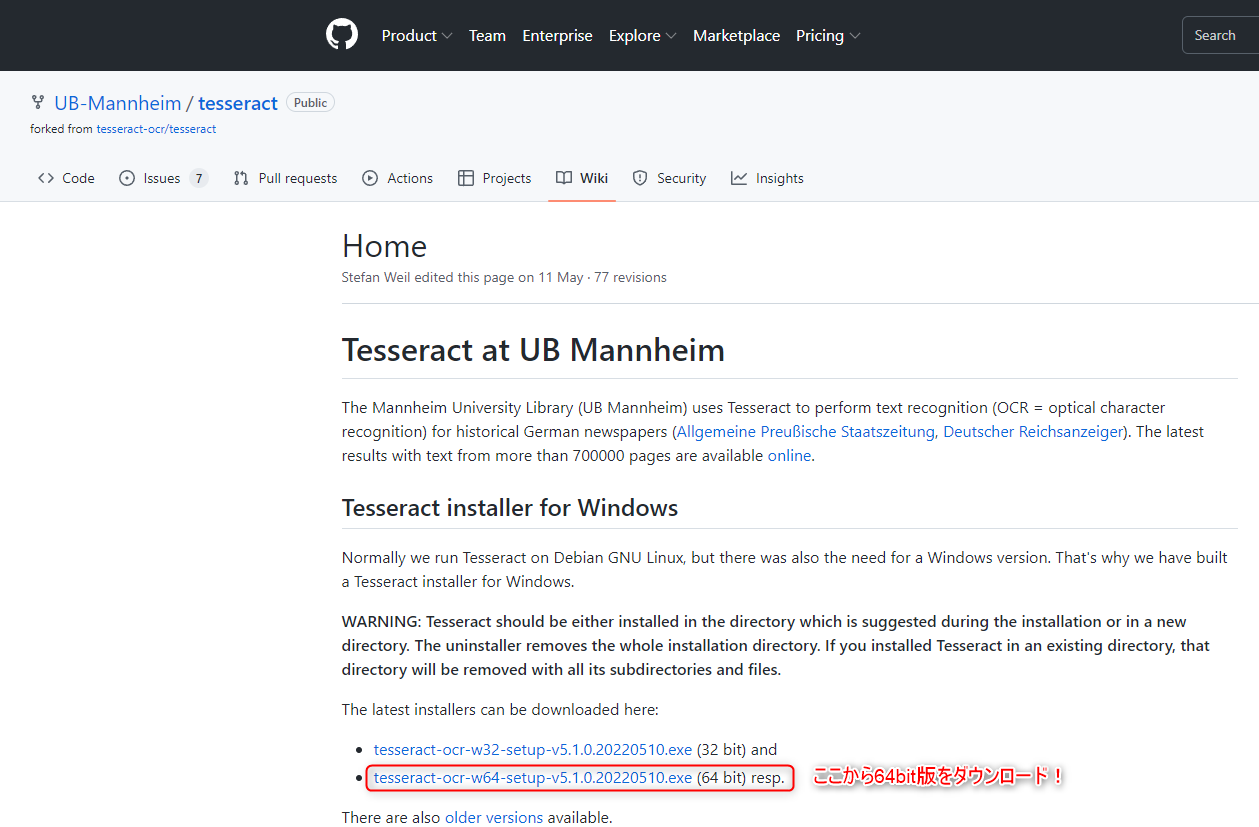
インストーラを入手する
TesseractはPyOCRのようなライブラリではなく外部ツールなので、インストーラを入手してインストールします。
インストールは以下からダウンロードできます。
インストールする
ダウンロードが完了したらダブルクリックして実行します。
警告が出ますが実行します。
(念のためウイルススキャンしました)

日本語に対応させる
進んでいくとインストール内容を選択する画面が表示されます。
ここで日本語用のスクリプトと言語データを追加します。
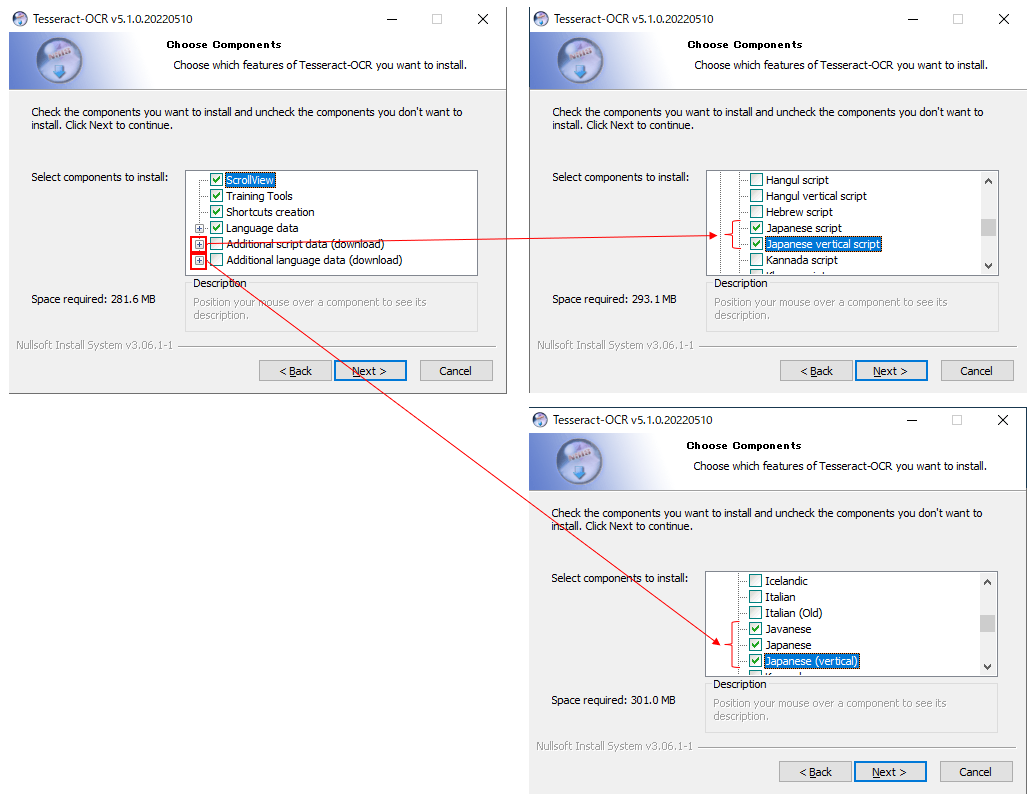
インストール完了
あとは指示通りに進めていくだけで完了です。
ドキュメントを作成する
ここまでで環境の準備が整いました。
今回の「文字認識をする」プロジェクトのフォルダをVSCodeから作成しましょう。
(VSCodeの基本操作の理解をするパートです)
フォルダを作成、選択する
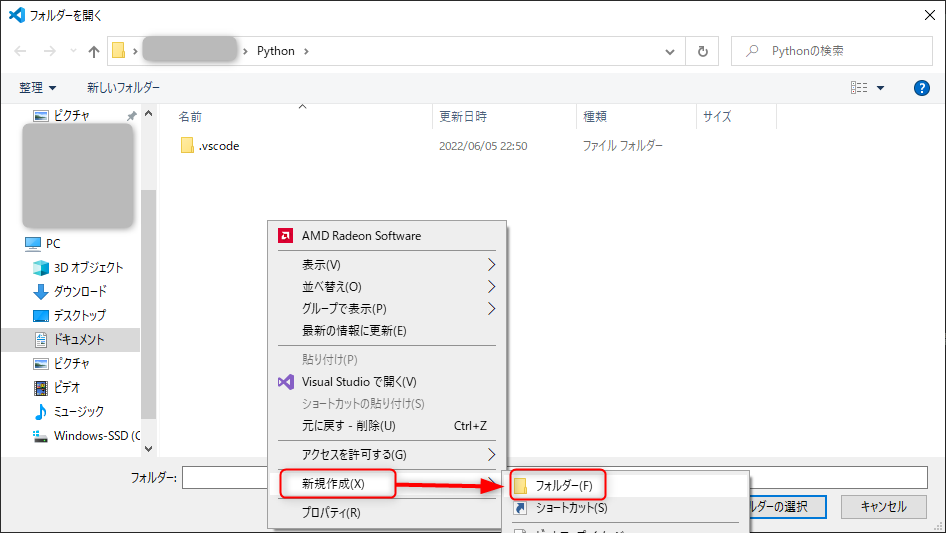
今回のプロジェクトをまとめるフォルダを作りましょう。
普段のようにエクスプローラーから作ってもいいですが、後々そのフォルダをVSCodeで開く必要があるので、一緒にやっちゃいます。
VSCodeのようこそ画面、もしくはツールバーの「ファイル」から「フォルダーを開く…」を選択します。

あとはそのまま通常通りにフォルダを作って選択し、「フォルダの選択」ボタンを押します。
管理人は今回適当な場所に「Python」フォルダを作り、その中に「OCR」というフォルダを作りました。
ここを以降の作業場所とします。
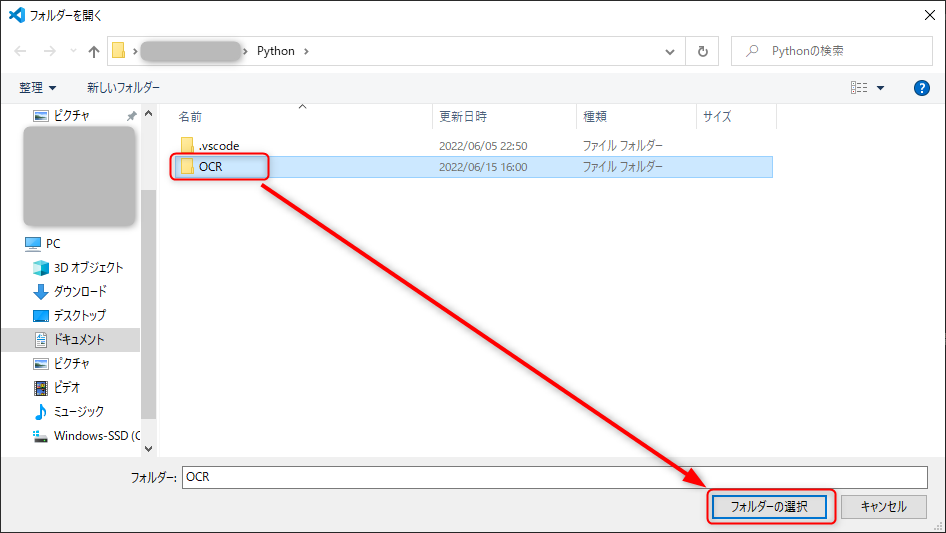
VSCodeのエクスプローラーにOCRフォルダが指定されました。
ここにソースファイルだったりを入れていきます。
ソースファイルを作成する
実際にPythonのコードを入力するソースファイルを作成します。
OCRフォルダの横にあるボタンからファイルを作成します。
(右クリック→新しいファイル でもできます)
ファイル名は「OCR.py」としておきましょう。
「OCR.py」というファイルが作成されて、編集状態になります。
Pythonの拡張子は“.py”です。
コードを記入したテキストファイルの拡張子を”.py”に変更すればPythonのソースファイルになります。
コードを書く
早速コードを書いていきましょう。
大まかな構成は以下の通りです。
- システムの利用を宣言する
- PyOCRを読み込む
- Tesseractのインストール場所をOSに教える
- OCRエンジンを取得する
- 画像を取得する
- 文字を取得する
- 取得した文字を出力する
完成品はコチラです。
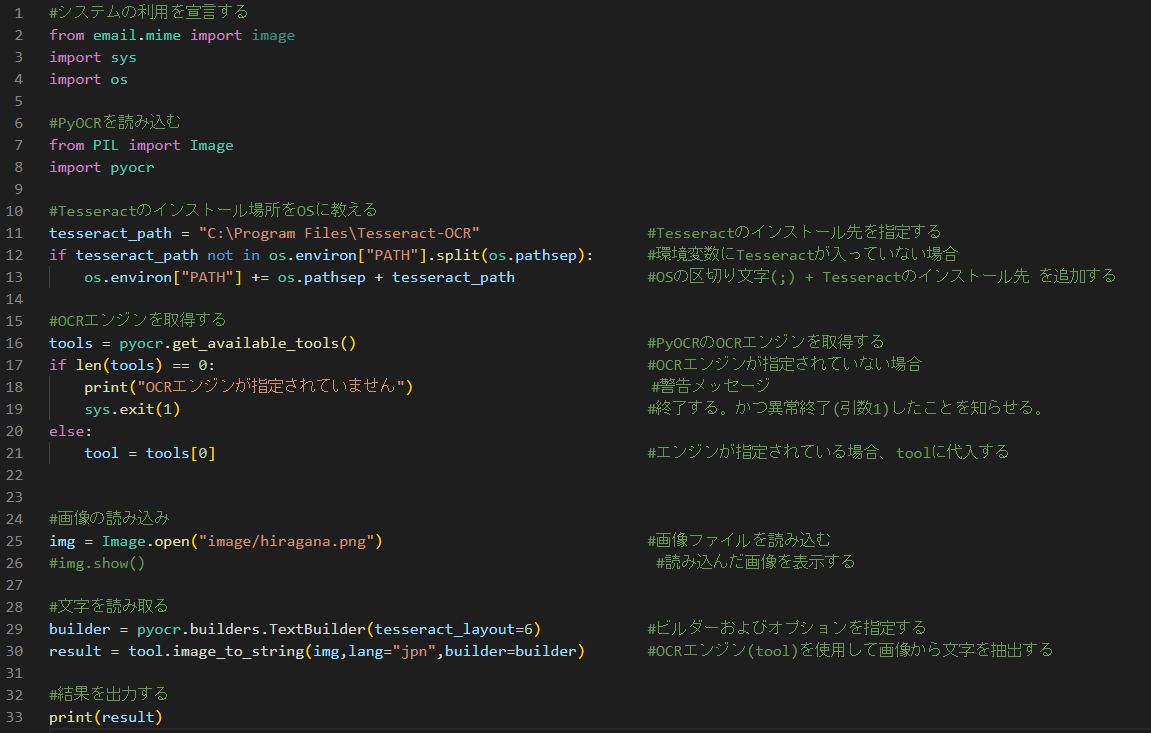
一つずつ見ていきましょう。
システムの利用を宣言する
環境変数を使用するため「OSおよびSYSを使います」という宣言をします。
#システムの利用を宣言する import os import sys
import os
「OSの機能を使うよ」の宣言
import sys
「システムの機能を使うよ」の宣言
※エラーが発生した際にプログラムを修正する処理に使用します。
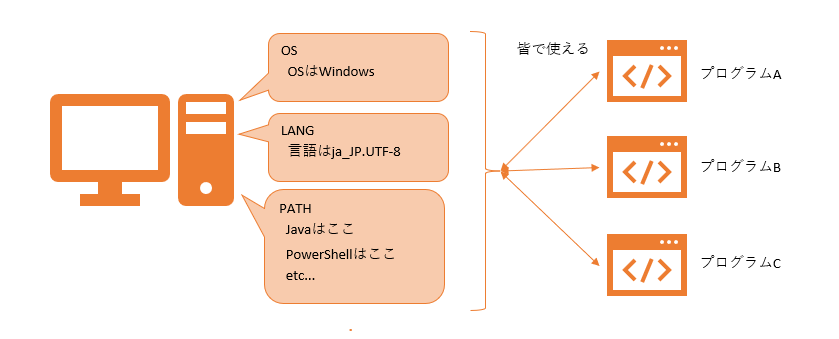
OSが持っている変数のこと。
色んなプログラムで共有できる。
今回は os.environ[“PATH”] で色んなプログラムのインストール先を持っているリストを使用する。
PyOCRを読み込む
「PyOCRを使います!」という宣言をします。
#PyOCRを読み込む from PIL import Image import pyocr
from PIL import Image
「Pillow(PIL)のImageという関数を使うよ」の宣言
import pyocr
「PyOCRを使うよ」の宣言
Tesseractのインストール場所をOSに教える
次にPyOCR経由でTesseractのOCRエンジンを使用するため、Tesseractのインストール先をOSに教えてあげます。
管理人の場合は特にインストール先など変更しなかったため、以下に使用するファイルが格納されていました。
C:\Program Files\Tesseract-OCR
#Tesseractのインストール場所をOSに教える
tesseract_path = "C:\Program Files\Tesseract-OCR"
if tesseract_path not in os.environ["PATH"].split(os.pathsep):
os.environ["PATH"] += os.pathsep + tesseract_path
やっていることは「環境変数のパスの一覧にTesseractが入っていなかったら追記する」という処理です。
OCRエンジンを取得する
PyOCRのOCRエンジンを取得し、Toolとして登録します。
IF文でOCRエンジンが見つからなかったらプログラムを終了します。
#OCRエンジンを取得する
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("OCRエンジンが指定されていません")
sys.exit(1)
else:
tool = tools[0]
画像を取得する
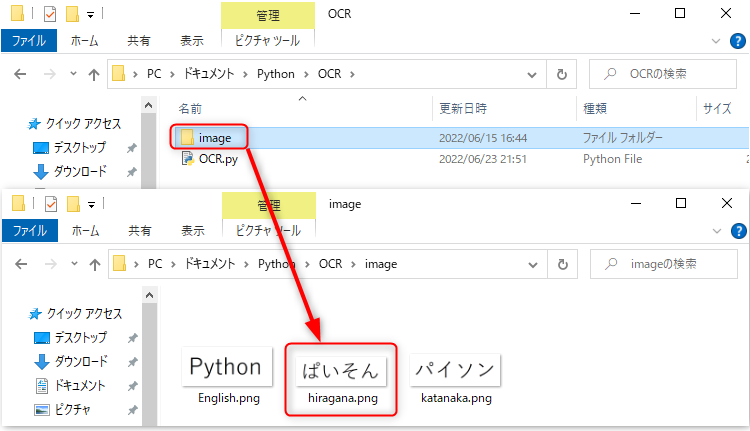
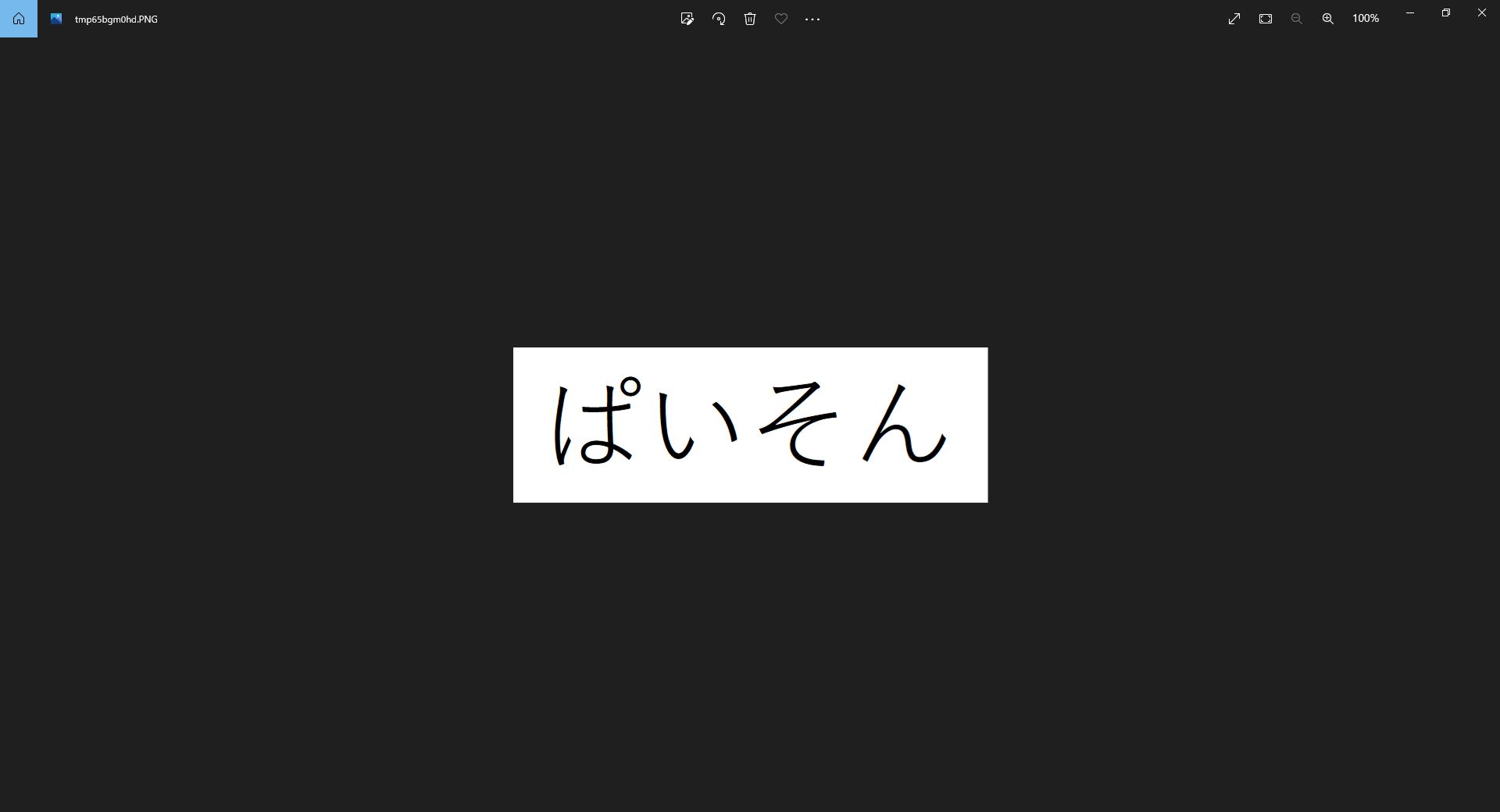
画像ファイルのパスを指定して読み込みます。
今回は以下に保存している「hiragana.png」を読み込んでみます。
#画像の読み込み
img = Image.open("image/hiragana.png")
正しく読み込めているかを確認するため、表示させる分も入れましょう。
#画像の読み込み
img = Image.open("image/hiragana.png")
img.show()
コードを入力して、画面右上の実行ボタン(もしくはF5キー)を押します。
ウィンドウが起動し、画像が表示されました。
ここまでの処理は問題なさそうです。
文字を取得する
画像が読み込めたので文字を読み取ります。
#文字を読み取る builder = pyocr.builders.TextBuilder(tesseract_layout=6) result = tool.image_to_string(img,lang="jpn",builder=builder)
やっていることは…
- ビルダー(PyOCRを実行してくれるもの?)と、その中で使用するTesseractのオプション(tesseract_layout)指定する
- 画像ファイル、読み取る言語、ビルダーを指定して、image_to_string関数で画像から文字を取得する
ビルダーの種類やTesseract_Layoutにもいろいろ種類があります。
読み取るもの(数字、文字など)によって変わるので、うまく読み取れないときは変えてみましょう。
詳細は以下の参考にさせていただいたサイト様をご参照ください。
(他力本願)
取得した文字を出力する
文字を取得したら出力しましょう。
#結果を出力する print(result)
ここは分かりやすいですね。
取得したresultをprintで出力するだけです。
結果を確認する
コードの入力が完了したので、実行して結果を確認しましょう。
画面下部のターミナルに結果が出力されます。
ターミナルが表示されていない場合は Ctrl+@ でターミナルが表示されます。

ばいそん…
精度はまだまだ改善の余地がありそうですね…
おわりに
お疲れさまでした!
精度は要改善ですが、ひとまずOCRはできましたね!
ここから精度を上げるも良し、複数行の画像やイラストなどが入った画像に挑戦するも良し、皆さんのやりたいことを広げていきましょう!




