
この記事では、OCR(画像から文字を読み取る)をした際に文字の位置を取得する方法を解説します。
元画像を加工したい場合などに利用できると思います。
管理人はOCRで読み取った文字をDeepLで翻訳し、元画像に重ねて表示する翻訳ソフトを作ることに挑戦しようと思っています。

前提
この記事では、事前にOCRを行うためのライブラリであるPyOCRを導入済みの状態から始めます。
まだ導入されていない方は以下のページを参照し…
- PyOCR
- Tesseract
を導入しておいてください。

目次
OpenCVを導入する
OCRで文字と座標を取得するために必要なPyOCRおよびTesseractは導入済みなので、あとは取得した座標を元画像にマークするために必要なOpenCVを導入します。
画像や動画を処理するのに必要な機能がまとめられたライブラリです。
今回は、文字として認識した範囲を四角で囲うために使用します。
インストール方法はPyOCR等と同じくpipコマンドです。
画面下部のターミナルにコマンドを入力してEnterキーで開始しましょう。
py -m pip install opencv-python

完了するとその旨が表示されます。
これで準備完了です!
座標を取得する
座標を取得する
文字の座標を取得するのは簡単です。
PyOCRのビルダーを”TextBuilder“から”WordBoxBuilder“に変更するだけです。
↓TextBuilderで文字の読み取りをした際の記事は以下を参照↓

取得した値を見てみる
WordBoxBuilderに変更して結果を取得してみましょう。
WordboxBuilderはリストで値を取得してきます。
取得元の画像はコチラ↓です。

試しにこんな感じでリストの値を出力してみます。

結果は以下の通り

読み取った文字の後に謎の4つの数字…
これは読み取った文字の座標です。

また、取得した結果には以下のように名称が設定されています。
その名称を指定することで、欲しい値だけを取り出すことが出来ます。
値:content
座標:position

↓結果↓
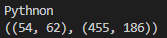
値と座標を分けて取得できました。
座標を元画像に書き込む
ここまでで画像から読み取った文字と座標を取得することが出来ました。
この座標をもとに、元画像に四角を書き込んでみましょう。
宣言
ようやくOpenCVの出番です!
まずは「OpenCVを使うよ」という宣言をしておきましょう。

書き込む用の画像の設定
そして、画像を読み込む箇所に「書き込む用の画像」を追加します。
OpenCVの画像読み込みは…
cv2.imread(画像ファイルパス)
で行います。

四角を書き込む
書き込む用の画像に四角を書き込みます。
四角(rectangle)の書き込みは…
cv2.rectangle(書き込む画像 , 左上座標 , 右下座標 , 枠の色 , 線の太さ)
で指定します。
その際の注意点が2つ
- 座標は(x,y)の形式で指定します。
Tesseractで取得した座標をposition[0]およびposition[1]で指定すればOKです。 - 色はRGB(赤、緑、青)ではなくBGR(青、緑、赤)の順番です。

書き込んだ画像を表示する
書き込んだ画像を表示します。
これで最後です。
OpenCVの画像表示は…
cv2.imshow(表示名 , 画像)
で行います。
しかし、そのままでは画像を一瞬表示して次の処理に移って消えてしまうため、キーが押されるまで停止させる必要があります。
cv2.waitKey(0)

これで必要な処理は完了です。
実行する
必要な処理を書き込んだので、実行してみましょう。
指定の通り、”image”という名称で四角が書き込まれた画像が表示されました!
四角も文字の範囲を正しく囲っていますね!
画像を変えて、2行の文字が書かれたものにしてみます。
結果は以下の通り。

正しく認識され、四角で囲われています!
これにて完了です!!
では、最後に全体を見てこの記事を終わりにしたいと思います。

#システムの利用を宣言する
import sys
import os
#PyOCRを読み込む
from PIL import Image
import pyocr
#OpenCVの利用を宣言する(画像に四角を書き込む際に使用)
import cv2
#Tesseractのインストール場所をOSに教える
tesseract_path = "C:\Program Files\Tesseract-OCR"
if tesseract_path not in os.environ["PATH"].split(os.pathsep):
os.environ["PATH"] += os.pathsep + tesseract_path
#OCRエンジンを取得する
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("OCRエンジンが指定されていません")
sys.exit(1)
else:
tool = tools[0]
#画像の読み込み
file_path = "image/English_2.png"
img = Image.open(file_path)
img2 = cv2.imread(file_path)
#文字と座標を読み取る
box_builder = pyocr.builders.WordBoxBuilder(tesseract_layout=6)
text_position = tool.image_to_string(img,lang="jpn",builder=box_builder)
#取得した座標と文字を出力するし、画像に枠を書き込む
for res in text_position:
print(res.content)
print(res.position)
cv2.rectangle(img2,res.position[0],res.position[1],(0,0,255),2)
#四角を書き込んだ画像を表示する
cv2.imshow("image",img2)
cv2.waitKey(0)
ここまでご覧いただきありがとうございました!
お疲れさまでした!




